Given the remarkable results of motion synthesis with diffusion models, a
natural question arises: how can we effectively leverage these models for mo-
tion editing? Existing diffusion-based motion editing methods overlook the
profound potential of the prior embedded within the weights of pre-trained
models, which enables manipulating the latent feature space; hence, they
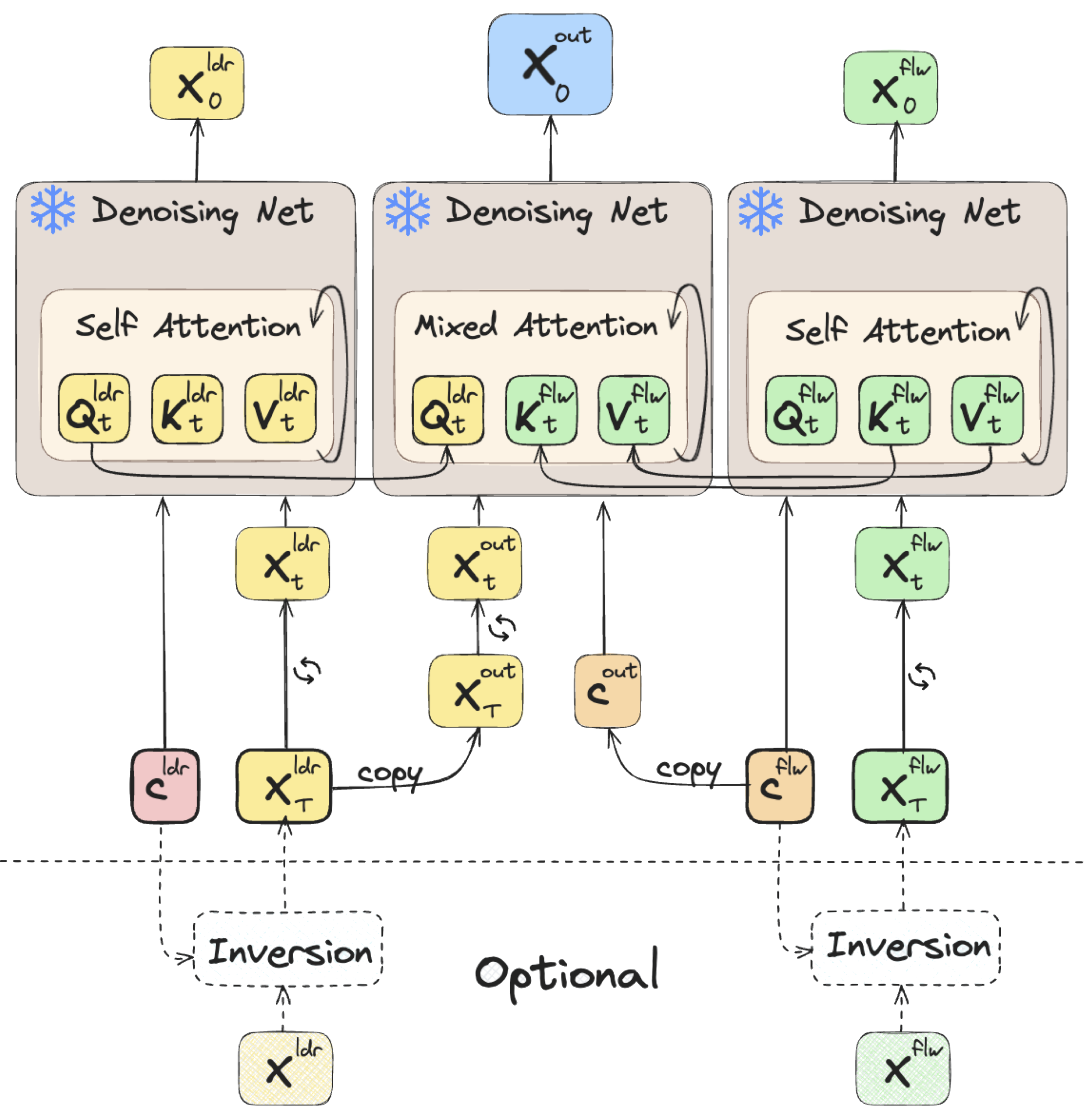
primarily center on handling the motion space. In this work, we explore the
attention mechanism of pre-trained motion diffusion models. We uncover the
roles and interactions of attention elements in capturing and representing
intricate human motion patterns, and carefully integrate these elements to
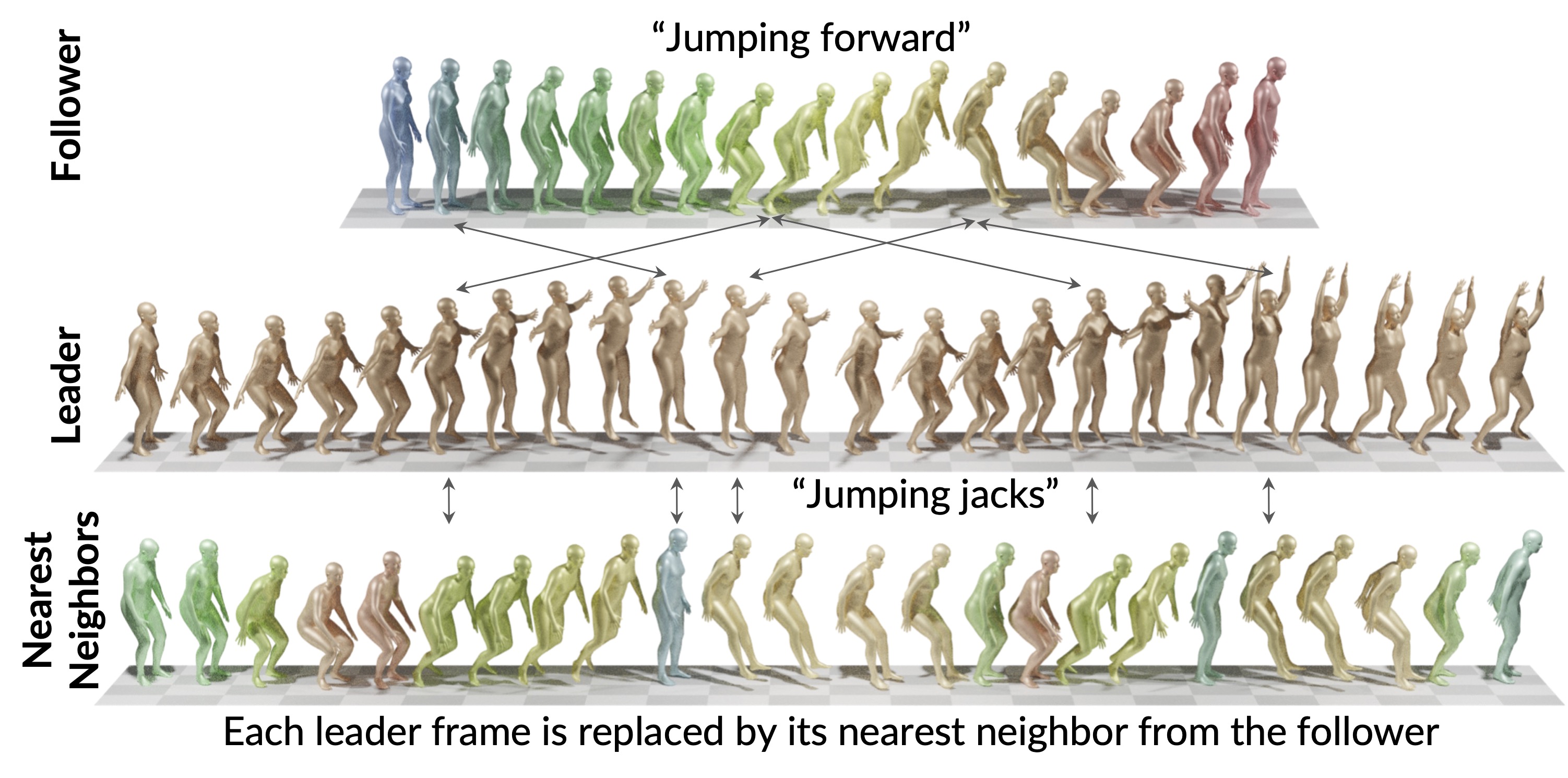
transfer a leader motion to a follower one while maintaining the nuanced
characteristics of the follower, resulting in zero-shot motion transfer. Editing
features associated with selected motions allows us to confront a challenge
observed in prior motion diffusion approaches, which use general directives
(e.g., text, music) for editing, ultimately failing to convey subtle nuances
effectively. Our work is inspired by how a monkey closely imitates what it
sees while maintaining its unique motion patterns; hence we call it Monkey
see, Monkey Do, and dub it MoMo. Employing our technique enables accom-
plishing tasks such as synthesizing out-of-distribution motions, style transfer,
and spatial editing. Furthermore, diffusion inversion is seldom employed
for motions; as a result, editing efforts focus on generated motions, limiting
the editability of real ones. MoMo harnesses motion inversion, extending its
application to both real and generated motions. Experimental results show
the advantage of our approach over the current art. In particular, unlike
methods tailored for specific applications through training, our approach is
applied at inference time, requiring no training.